
The recent Google Chrome Developer slides for the Chrome DevTools for Agents launch, one tiny detail probably caught your eye…
Tucked inside a bullet point about context optimization was a mention of llms.txt.

h/t Crystal Carter via Whatsapp for the image.
Predictably, parts of the tech industry reacted exactly how you would expect.
People started claiming that Google is tracking this file, and that it is time to audit your site to rank better in chat assistants.
But if you actually look at the context of the slide, and the broader documentation Google is pushing out, the reality is far more grounded.
Before you convince yourself to upend your roadmap for a text file, let us look at what is actually happening.
What the slide actually shows
The slide points out that seeing llms.txt in DevTools means you can check how many context tokens your site documentation file is consuming before an agent even starts executing tasks.
When you look at the official Chrome Developers blog post for the DevTools for Agents launch, llms.txt is not even mentioned.
| Document | Is llms.txt mentioned? |
| DevTools for agents main LP | No |
| DevTools for agents 1.0 | No |
| 15 updates from Google I/O 2026 | No |
Instead, the focus is heavily on WebMCP, memory leak debugging, and the accessibility tree.
What we can infer from this is that the inclusion of llms.txt on that slide is strictly from a local debugging and optimization standpoint.
It was likely bundled into the presentation alongside validating WebMCP tools.
It is a tool for developers to test their own agents or understand token bloat when an agent fetches local documentation. It is not a secret backdoor to rank better.
Conflicting messaging
Right now, Google documentation explicitly calls llms.txt an emerging convention.
The language used by Google engineers when talking about these agent tools consistently refers to your agents and your site.
This is about equipping developers to build and test autonomous coding and browsing agents that can navigate their own web apps without breaking.
Original purpose
When Jeremy Howard originally proposed the llms.txt specification, it was an elegant concept. It was a clean, markdown-based roadmap at the root of a site to help LLMs digest high-level structure without drowning in messy HTML.
Andrej Karpathy similarly looked at it as a smart way to help the AI era access content better.
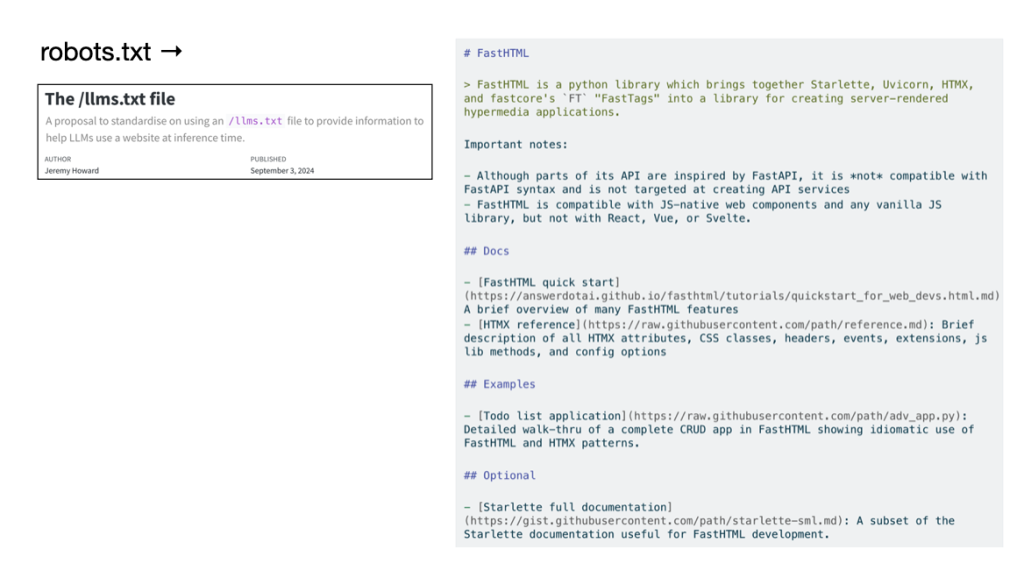
So as an example you can have robots.txt on your domain, and instruct, well advise I suppose, web crawlers on how to behave on your website. In the same way you can have maybe llms.txt file which is just a simple markdown that’s telling LLMs what this domain is about and this is readable to an LLM. If it had to instead get the HTML of your webpage and try to parse it, this is very error prone and difficult and will screw it up and its not going to work. So we can directly speak to the LLM and it’s worth it.
A huge amount of documentation is currently written for people. So you will see things like lists, bold, and pictures and this is not directly accessible by an LLM. So I see some of the services are transitioning a lot of their docs to be specifically for LLMs. So Vercel and Stripe as an example are early movers here, but there are a few more that I’ve seen already and they offer their documentation in markdown.
Markdown is super easy for LLMs to understand. This is great.
Neither of them ever said it was a silver bullet to rank in chat applications.
But as soon as a major tech company puts a term on a slide, a certain subset of the industry pulls it entirely out of context.
They weaponise it into content, causing a tsunami of panic optimisation.
Being able to make pre-AI era and human focused content accessible to LLMs more readily will be a huge leap forward, but the level to which it is prone to abuse right now leaves it dangerous to adopt.
Is llms.txt a bad idea?
Absolutely not.
It is a great, lightweight convention that might very well become a fully adopted web standard in the next few years.
But its sudden appearance in Chrome DevTools is not a sign that Google is forcing you to optimize your codebase for AI algorithms.
It is a signal that Chrome is building an environment for debugging local agent behavior.
Optimise your accessibility tree because it helps humans and happens to help agents navigate.
Build out WebMCP if you want to expose structured tools.
But do not rush to dump resources into llms.txt expecting an overnight traffic miracle.
Leave a Reply